

Пусть задан набор уникальных элементов. И задан некоторый ключ х для поиска.
Var mass: array [1..n] of Byte;
— данные не упорядочены.
— количество элементов фиксировано.
Алгоритм последовательного поиска начинается с первого элемента данных. Последовательно сравнивается каждый элемент с ключом до тех пор, пока не будет найден искомый элемент или достигнут конец набора данных. Т.о., условия завершения алгоритма:
— элемент найден, т.е. некоторый  -ый элемент
-ый элемент ;
;
— весь массив просмотрен и совпадения не обнаружено.
Порядок выполнения последовательного поиска:
ш.1) перейти в начало набора
ш.2) пока не достигнут конец набора и текущий элемент не равен искомому → ш.3, иначе ш.4
ш.3) переход к следующему элементу → ш.2
ш.4) если в результате выполнения цикла значение индекса превысило значение значения крайнего индекса набора, тогда искомый элемент не найден, иначе — найден.
while  and
and  do
do
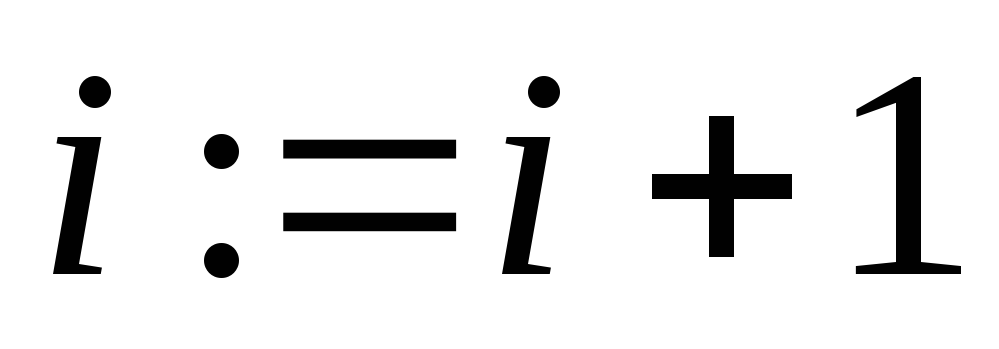 ;
;
if  then
then
На каждом шаге происходит увеличение индекса и проверка 2-ух условий. Алгоритм можно упростить по следующему принципу: при нескольких проверках во внутреннем цикле следует свести их к минимуму (одной), при этом следует гарантировать, что совпадение произойдет всегда.
Последовательный поиск с барьером
Является улучшением алгоритма последовательного поиска.
В последовательности создается «барьер»: последним дописывается элемент, равный искомому. В таком случае, ключ ищется до тех пор, пока не будет совпадения (или найден элемент, или достигнут барьер).
 ;
;

while ( ) do
) do
 ;
;
if  then
then
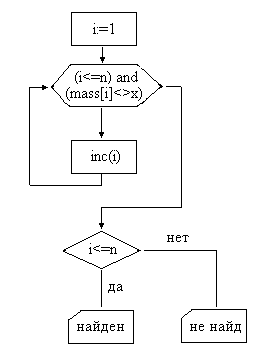
Блок схема последовательного поиска
Блок схема последовательного поиска с барьером

(поиск делением пополам, двоичный поиск)
Совершенно очевидно, что других способов убыстрения поиска не существует, если, конечно, нет еще какой-либо информации о данных, среди которых идет поиск. Хорошо известно, что поиск можно сделать значительно более эффективным, если данные будут упорядочены.
Приведем алгоритм, основанный на знаний того, что массив а упорядочен, т.е. удовлетворяет условию  , где
, где 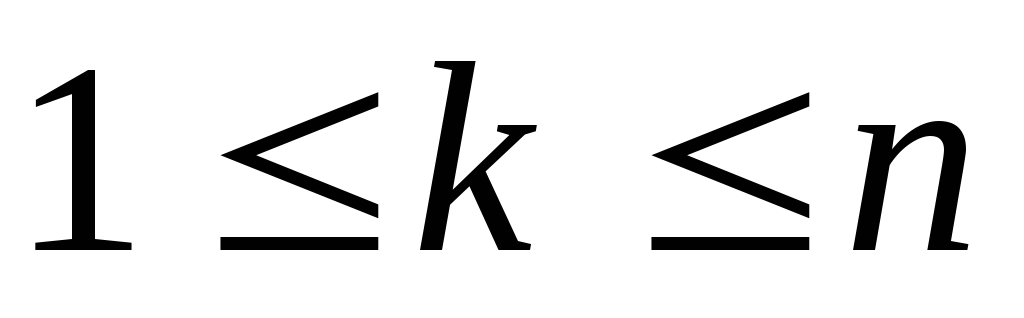
— количество элементов фиксировано.
Алгоритм решает задачу, уменьшая размер рассматриваемого поддиапазона, в котором может находиться ключ x.
В начале в качестве диапазона рассматривается весь массив, в котором ищется средний элемент. Затем средний элемент сравнивается с ключом:
— если он меньше ключа, то делается вывод о том, что все элементы с индексами, меньшими индекса среднего элемента, можно исключить из дальнейшего поиска;
— если же средний элемент больше искомого значения, то исключаются элементы с индексами, большими индекса среднего элемента.
Процесс поиска продолжается до тех пор, пока число x не будет найдено или пока диапазон элементов не окажется пустым.
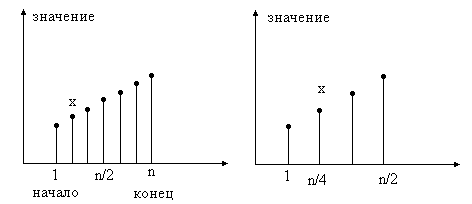
Рис.4. Поиск делением пополам
ш.1) установить левую и правую границы диапазона;
ш.2) если диапазон не пуст то → ш.3), иначе→ ш.5)
ш.3) вычислить индекс среднего элемента;
ш.4) сравнить средний элемент с ключом:
если средний элемент равен ключу, то — успешный поиск, завершение поиска, иначе если средний элемент больше ключа, изменить правую границу, → ш.3); иначе если средний элемент меньше ключа, изменить левую границу, → ш.3);
ш.5) элемент не найден.
 ;
;

while ( ) do
) do

if  then
then
else if 

 ;
;
if  then
then

Способы улучшения алгоритма:
1. поменять местами заголовки условных операторов. Проверку на равенство можно выполнять в последнюю очередь, так как она встречается единожды и приводит к окончанию работы.
2. Отказаться от окончания поиска при фиксации совпадения.
Пусть задан набор уникальных элементов. И задан некоторый ключ х для поиска.
Var mass: array [1..n] of Byte;
— данные не упорядочены.
— количество элементов фиксировано.
Алгоритм последовательного поиска начинается с первого элемента данных. Последовательно сравнивается каждый элемент с ключом до тех пор, пока не будет найден искомый элемент или достигнут конец набора данных. Т.о., условия завершения алгоритма:
— элемент найден, т.е. некоторый -ый элемент;
— весь массив просмотрен и совпадения не обнаружено.
Порядок выполнения последовательного поиска:
ш.1) перейти в начало набора
ш.2) пока не достигнут конец набора и текущий элемент не равен искомому → ш.3, иначе ш.4
ш.3) переход к следующему элементу → ш.2
ш.4) если в результате выполнения цикла значение индекса превысило значение значения крайнего индекса набора, тогда искомый элемент не найден, иначе — найден.
while and do
;
if then
На каждом шаге происходит увеличение индекса и проверка 2-ух условий. Алгоритм можно упростить по следующему принципу: при нескольких проверках во внутреннем цикле следует свести их к минимуму (одной), при этом следует гарантировать, что совпадение произойдет всегда.
Последовательный поиск с барьером
Является улучшением алгоритма последовательного поиска.
В последовательности создается «барьер»: последним дописывается элемент, равный искомому. В таком случае, ключ ищется до тех пор, пока не будет совпадения (или найден элемент, или достигнут барьер).
;
while () do
;
if then
Блок схема последовательного поиска
Блок схема последовательного поиска с барьером
(поиск делением пополам, двоичный поиск)
Совершенно очевидно, что других способов убыстрения поиска не существует, если, конечно, нет еще какой-либо информации о данных, среди которых идет поиск. Хорошо известно, что поиск можно сделать значительно более эффективным, если данные будут упорядочены.
Приведем алгоритм, основанный на знаний того, что массив а упорядочен, т.е. удовлетворяет условию , где
— количество элементов фиксировано.
Алгоритм решает задачу, уменьшая размер рассматриваемого поддиапазона, в котором может находиться ключ x.
В начале в качестве диапазона рассматривается весь массив, в котором ищется средний элемент. Затем средний элемент сравнивается с ключом:
— если он меньше ключа, то делается вывод о том, что все элементы с индексами, меньшими индекса среднего элемента, можно исключить из дальнейшего поиска;
— если же средний элемент больше искомого значения, то исключаются элементы с индексами, большими индекса среднего элемента.
Процесс поиска продолжается до тех пор, пока число x не будет найдено или пока диапазон элементов не окажется пустым.
Рис.4. Поиск делением пополам
ш.1) установить левую и правую границы диапазона;
ш.2) если диапазон не пуст то → ш.3), иначе→ ш.5)
ш.3) вычислить индекс среднего элемента;
ш.4) сравнить средний элемент с ключом:
если средний элемент равен ключу, то — успешный поиск, завершение поиска, иначе если средний элемент больше ключа, изменить правую границу, → ш.3); иначе если средний элемент меньше ключа, изменить левую границу, → ш.3);
ш.5) элемент не найден.
;
while () do
if then
else if
;
if then
Способы улучшения алгоритма:
1. поменять местами заголовки условных операторов. Проверку на равенство можно выполнять в последнюю очередь, так как она встречается единожды и приводит к окончанию работы.
2. Отказаться от окончания поиска при фиксации совпадения.
Для нахождения некоторого элемента (ключа) в заданном неупорядоченном массиве используется алгоритм линейного (последовательного) поиска. Он работает как с неотсортированными массивами, так и отсортированными, но для вторых существуют алгоритмы эффективнее линейного поиска.
Эту неэффективность компенсируют простая реализация алгоритма и сама возможность применять его к неупорядоченным последовательностям. Здесь, а также при рассмотрении всех других алгоритмов поиска, будем полагать, что в качестве ключа выступает некоторая величина, по мере выполнения алгоритма, сравниваемая именно со значениями элементов массива.
Слово «последовательный» содержит в себе основную идею метода. Начиная с первого, все элементы массива последовательно просматриваются и сравниваются с искомым. Если на каком-то шаге текущий элемент окажется равным искомому, тогда элемент считается найденным, и в качестве результата возвращается номер этого элемента, либо другая информация о нем. (Далее, в качестве выходных данных будет выступать номер элемента). Иначе, следуют возвратить что-то, что может оповестить о его отсутствии в пройденной последовательности.
Ниже, на примере фигур, наглядно демонстрируется работа алгоритма линейного поиска. В качестве искомого элемента (в данном случае это квадрат) задается фигура, и она поочередно сравнивается со всеми имеющимися фигурами до тех пор, пока не будет найдена тождественная ей фигура, или окажется, что в данном множестве таковой нет.

Примечателен тот факт, что имеется вероятность наличия нескольких элементов с одинаковыми значениями, совпадающими со значением ключа. В таком случае, если нет конкретных условий, можно, например, за результирующий взять номер первого найденного элемента (реализовано в листинге ниже), или записать в массив номера всех тождественных элементов.