

Содержание урока:

 | 14.1. Кодировка ASCII и её расширения |  |
| Кодирование текстовой информации |  | 14.2. Стандарт Unicode |
14.1. Кодировка ASCII и её расширения
Основой для компьютерных стандартов кодирования символов послужил код ASCII (American Standard Code for Information Interchange) — американский стандартный код для обмена информацией, разработанный в 1960-х годах в США и применявшийся для любых, в том числе и некомпьютерных, способов передачи информации (телеграф, факсимильная связь и т. д.). Этот код 7-битовый: общее количество символов составляет 2 7 = 128, из них первые 32 символа — управляющие, а остальные — изображаемые, т. е. имеющие графическое изображение. К изображаемым символам в ASCII относятся буквы латинского алфавита (прописные и строчные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы. Кодировка ASCII приведена в табл. 3.8.
Таблица 3.8
Кодировка ASCII
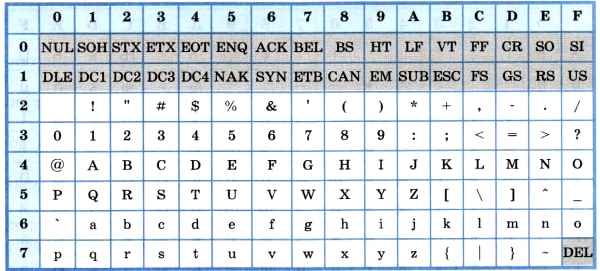
Хотя для кодирования символов в ASCII достаточно 7 битов, в памяти компьютера под каждый символ отводится ровно 1 байт (8 битов), при этом код символа помещается в младшие биты, а в старший бит заносится 0.
Например, 01000001 — код прописной латинской буквы «А»; с помощью шестнадцатеричных цифр его можно записать как 41.
Стандарт ASCII рассчитан на передачу только английского текста. Со временем возникла необходимость кодирования и неанглийских букв. Во многих странах для этого стали разрабатывать расширения ASCII -кодировки, в которых применялись однобайтовые коды символов. При этом первые 128 символов кодовой таблицы совпадали с кодировкой ASCII, а остальные (со 128-го по 255-й) использовались для кодирования букв национального алфавита, символов национальной валюты и т. п. Из-за несогласованности этих разработок для многих языков было создано несколько вариантов кодовых таблиц (например, для русского языка их было создано около десятка!).
Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер. Для русского языка наиболее распространёнными стали однобайтовые кодовые таблицы CP-866, Windows-1251 (табл. 3.9) и КОИ-8 (табл. 3.10). В них первые 128 символов совпадают с ASCII-кодировкой, а русские буквы размещены во второй части таблицы. Обратите внимание на то, что коды русских букв в этих кодировках различны.
Таблица 3.9
Кодировка Windows-1251
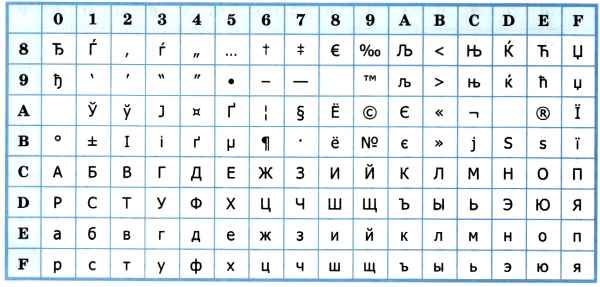
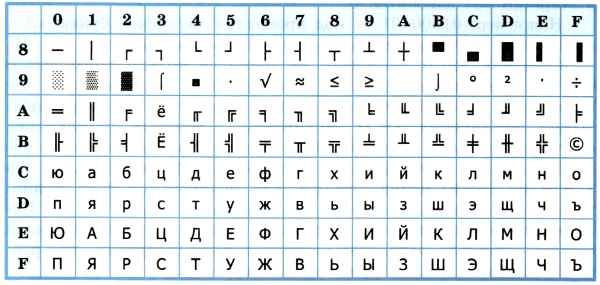
Таблица 3.10
Кодировка КОИ-8
Мы выяснили, что при нажатии на алфавитно-цифровую клавишу в компьютер посылается некоторая цепочка нулей и единиц. В текстовых файлах хранятся не изображения символов, а их коды.
При выводе текста на экран монитора или принтера необходимо восстановить изображения всех символов, составляющих данный текст, причём изображения эти могут быть разнообразны и достаточно причудливы. Внешний вид выводимых на экран символов кодируется и хранится в специальных шрифтовых файлах. Современные текстовые процессоры умеют внедрять шрифты в файл. В этом случае файл содержит не только коды символов, но и описание используемых в этом документе шрифтов. Кроме того, файлы, создаваемые с помощью текстовых процессоров, включают в себя и такие данные о форматировании текста, как его размер, начертание, размеры полей, отступов, межстрочных интервалов и другую дополнительную информацию.
Cкачать материалы урока
Содержание урока
Общий подход
Общий подход
Поскольку в современных компьютерах информация всех видов представлена в двоичном коде, нужно разобраться, как закодировать символы в виде цепочек нулей и единиц. Например, можно предложить способ, основанный на системе Брайля для незрячих людей. В нём каждый символ кодируется с помощью 6 точек, расположенных в два столбца. В каждой точке может быть выпуклость, которая чувствуется на ощупь. Обозначив выпуклость единицей, а её отсутствие — нулём, можно закодировать первые буквы русского алфавита следующим образом:
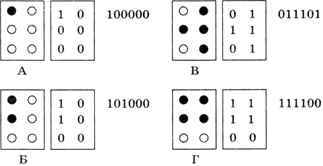
Здесь двоичный код строится так: строки полученной таблицы, состоящей из цифр 0 и 1, выписываются одна за другой в строчку. Так как используются всего 6 точек, количество символов, которые можно закодировать, равно 2 6 = 64 (в реальной системе Брайля 63 символа, потому что символ, в коде которого нет ни одной выпуклости, невозможно обнаружить на ощупь).
Понятно, что совершенно не обязательно использовать код Брайля. Главное — каждому используемому символу как-то сопоставить цепочку нулей и единиц, например составить таблицу «символ — код». На практике поступают следующим образом:
1) определяют, сколько символов нужно использовать (обозначим это число через N);
2) определяют нужное количество k двоичных разрядов так, чтобы с их помощью можно было закодировать не менее N разных последовательностей (т. е. 2 k ≥ N);
3) составляют таблицу, в которой каждому символу сопоставляют код (номер) — целое число в интервале от 0 до 2 k — 1;
4) коды символов переводят в двоичную систему счисления.
В текстовых файлах (которые не содержат оформления, например, в файлах с расширением txt) хранятся не изображения символов, а их коды. Откуда же компьютер берет изображения символов, когда выводит текст на экран? Оказывается, при этом с диска загружается шрифтовой файл (он может иметь, например, расширение fon, ttf, otf), в котором хранятся изображения, соответствующие кодам 1 . Именно эти изображения и выводятся на экран. Это значит, что при изменении шрифта текст, показанный на экране, может выглядеть совсем по-другому. Например, многие шрифты не содержат изображений русских букв. Поэтому, когда вы передаёте (или пересылаете) кому-то текстовый файл, нужно убедиться, что у адресата есть использованный вами шрифт. Современные текстовые процессоры умеют внедрять шрифты в файл; в этом случае файл содержит не только коды символов, но и шрифтовые файлы. Хотя файл увеличивается в объёме, адресат гарантированно увидит его в таком же виде, что и вы.
1 Существуют специальные программы, позволяющие создавать и редактировать шрифты, например Fontlab Studio:
http://www.fontlab.com/font-editor/fontlab-studio/
Следующая страница  Кодировка ASCII и её расширения
Кодировка ASCII и её расширения
Cкачать материалы урока
Материал для самостоятельного изучения по теме Лекции 2
Кодировочная таблица ASCII (ASCII — American Standard Code for Information Interchange — Американский стандартный код для обмена информацией).
Всего с помощью таблицы кодирования ASCII (рисунок 1) можно закодировать 256 различных символов. Эта таблица разделена на две части: основную (с кодами от OOh до 7Fh) и дополнительную (от 80h до FFh, где буква h обозначает принадлежность кода к шестнадцатеричной системе счисления).

Для кодировки одного символа из таблицы отводится 8 бит (1 байт). При обработке текстовой информации один байт может содержать код некоторого символа — буквы, цифры, знака пунктуации, знака действия и т.д. Каждому символу соответствует свой код в виде целого числа. При этом все коды собираются в специальные таблицы, называемые кодировочными. С их помощью производится преобразование кода символа в его видимое представление на экране монитора. В результате любой текст в памяти компьютера представляется как последовательность байтов с кодами символов.
Например, слово hello! будет закодировано следующим образом (таблица 1).
| Символ | h | e | I | I | o | ! |
| Код двоичный | ||||||
| Код десятичный |
На рисунке 1 представлены символы, входящие в стандартную (английскую) и расширенную (русскую) кодировку ASCII.
Первая половина таблицы ASCII стандартизована. Она содержит управляющие коды (от 00h до 20h и 77h). Эти коды из таблицы изъяты, так как они не относятся к текстовым элементам. Здесь же размещаются знаки пунктуации и математические знаки: 2lh — !, 26h — &, 28h — (, 2Bh -+. большие и малые латинские буквы: 41h — A, 61h – а.
Вторая половина таблицы содержит национальные шрифты, символы псевдографики, из которых могут быть построены таблицы, специальные математические знаки. Нижнюю часть таблицы кодировок можно заменять, используя соответствующие драйверы — управляющие вспомогательные программы. Этот прием позволяет применять несколько шрифтов и их гарнитур.
Дисплей по каждому коду символа должен вывести на экран изображение символа – не просто цифровой код, а соответствующую ему картинку, так как каждый символ имеет свою форму. Описание формы каждого символа хранится в специальной памяти дисплея — знакогенераторе. Высвечивание символа на экране дисплея IBМ PC, например, осуществляется с помощью точек, образующих символьную матрицу. Каждый пиксел в такой матрице является элементом изображения и может быть ярким или темным. Темная точка кодируется цифрой 0, светлая (яркая)- 1. Если изображать в матричном поле знака темные пикселы точкой, а светлые — звездочкой, то можно графически изобразить форму символа.
Люди в разных странах используют символы для записи слов их родных зыков. В наши дни большинство приложений, включая системы электронной почты и вэб-браузеры, являются чисто 8-битными, то есть они могут показывать и корректно воспринимать лишь 8-битные символы, согласно стандарту ISO-8859-1.
Существует более 256 символов в мире (если учесть кириллицу, арабский, китайский, японский, корейский и тайский языки), а также появляются все новые и новые символы. И это создает следующие пробелы для многих пользователей:
Невозможно использовать символы различных наборов кодировок в одном и том же документе. Так как каждый текстовый документ использует свой собственный набор кодировок, то возникают большие трудности с автоматическим распознаванием текста.
Появляются новые символы (например: Евро), вследствие чего ISO разрабатывает новый стандарт ISO-8859-15, который весьма схож со стандартом ISO-8859-1. Разница состоит в следующем: из таблицы кодировки старого стандарта ISO-8859-1 были убраны символы обозначения старых валют, которые не используются в настоящее время, для того, чтобы освободить место под вновь появившиеся символы (такие, как Евро). В результате у пользователей на дисках могут лежать одни и те же документы, но в разных кодировках. Решением этих проблем является принятие единого международного набора кодировок, который называется универсальным кодированием или Unicode.
Не нашли то, что искали? Воспользуйтесь поиском:
Лучшие изречения: Как то на паре, один преподаватель сказал, когда лекция заканчивалась — это был конец пары: "Что-то тут концом пахнет". 8413 —  | 8030 —
| 8030 —  или читать все.
или читать все.
78.85.5.224 © studopedia.ru Не является автором материалов, которые размещены. Но предоставляет возможность бесплатного использования. Есть нарушение авторского права? Напишите нам | Обратная связь.
Отключите adBlock!
и обновите страницу (F5)
очень нужно