

Главное нужно указать изображение с текстом на вашем компьютере или телефоне, обязательно выбрать основной язык текста и нажать кнопку OK внизу страницы. Остальные настройки уже выставлены по умолчанию.
Пример сфотографированного текста из книги и скриншот распознанного текста на этой фотографии: 

В зависимости от размера исходного изображения и количества текста обработка может продлиться около 1 минуты.
Для достижения лучшего результата распознания текста желательно обратить внимание на подсказки возле настроек. Перед обработкой изображение нужно повернуть на нормальный угол, чтобы текст шёл в правильном направлении и небыл перевёрнут вверх ногами, а также желательно обрезать лишние однотонные края без текста, если они есть.
Обе OCR-программы для распознования текста отличаются друг от друга и могут давать разные результаты, что позволяет выбрать наиболее приемлемый вариант из двух.
Исходное изображение никак не изменяется, вам будет предоставлен распознанный текст в обычном текстовом документе в формате .txt с кодировкой utf-8 и после обработки его можно будет открыть прямо в окне браузера или же после скачивания – в любом текстовом редакторе.
который поможет получить напечатанный текст из PDF документов и фотографий
Принцип работы ресурса
Отсканируйте или сфотографируйте текст для распознавания

Загрузите файл
Выберите язык содержимого текста в файле

После обработки файла, получите результат * длительность обработки файла может составлять до 60 секунд
- Форматы файлов
- Изображения: jpg, jpeg, png
- Мульти-страничные документы: pdf
- Сохранение результатов
- Чистый текст (txt)
- Adobe Acrobat (pdf)
- Microsoft Word (docx)
- OpenOffice (odf)
Наши преимущества
- Легкий и удобный интерфейс
- Мультиязычность
Сайт переведен на 9 языков - Быстрое распознавание текста
- Неограниченное количество запросов
- Отсутствие регистрации
- Защита данных. Данные между серверами передаются по SSL + автоматически будут удалены
- Поддержка 35+ языков распознавания текста
- Использование движка Tesseract OCR
- Распознавание области изображения (в разработке)
- Обработано более чем 5.1M+ запросов
Основные возможности

Распознавание отсканированных файлов и фотографий, которые содержат текст
Форматирование бумажных и PDF-документов в редактируемые форматы
Сегодня (3.08.2018) мы обновили наш сайт.
Обновления коснулись интерфейса и добавления нового функционала:
• загрузка файлов перетаскиванием;
• в результатах возможность экспорта документа в Doc, Google Docs, pdf;
• перевод текста;
• проверка орфографии;
Сайт стал лучше и удобнее для пользователей. Но ещё много функций и дополнений мы запланировали реализовать в будущем.
0.5.2 (26.11.2018): Добавлен функционал для удаления запросов из истории
Если Вы нашли какие-то баги, пожалуйста, сообщите нам, отправив письмо на email: web(собака)img2txt.com
Спасибо.
Поддерживаемые языки:
Русский, Українська, English, Arabic, Azerbaijani, Azerbaijani — Cyrillic, Belarusian, Bengali, Tibetan, Bosnian, Bulgarian, Catalan; Valencian, Cebuano, Czech, Chinese — Simplified, Chinese — Traditional, Cherokee, Welsh, Danish, Deutsch, Greek, Esperanto, Estonian, Basque, Persian, Finnish, French, German Fraktur, Irish, Gujarati, Haitian; Haitian Creole, Hebrew, Croatian, Hungarian, Indonesian, Icelandic, Italiano, Javanese, Japanese, Georgian, Georgian — Old, Kazakh, Kirghiz; Kyrgyz, Korean, Latin, Latvian, Lithuanian, Dutch; Flemish, Norwegian, Polish Język polski, Portuguese, Romanian; Moldavian, Slovakian, Slovenian, Spanish; Castilian, Spanish; Castilian — Old, Serbian, Swedish, Syriac, Tajik, Thai, Turkish, Uzbek, Uzbek — Cyrillic, Vietnamese
© 2014-2019 img2txt Сервис распознавания изображений / v.0.6.4.1
Работая с различными графическими файлами, нам может понадобиться извлечь текст из нужного нам изображения. Разумеется, это можно сделать вручную, просто набрав в каком-либо текстовом редакторе текст с имеющейся картинки. Но если объём такого текста огромен, тогда сам процесс набора может затянуться на неопределённое время. Предлагаем читателю существенно упростить процедуру, и использовать для копирования текста специальные сервисы. Ниже разберём, каким образом можно скопировать текст с любой картинки в режиме онлайн. А также какие инструменты нам в этом помогут.
Как при помощи онлайн-сервисом можно скопировать текст с изображения
Технология, которая поможет нам перекопировать надпись с картинки, носит название «OCR» («Optical Character Recognition – оптическое распознавание символов) . Первый патент на оптическое распознавание текста был выдан в Германии ещё в далёком 1929 году. С тех пор наука шагнула далеко вперёд, и качество распознавания текстов существенно выросло. К примеру, в случае латинских символов качество распознавания может достигать 99% всего текста. В случае же кириллицы этот процент несколько меньше, что поясняется «латинским» акцентом большинства современных сервисов и программ.
Эффективное распознавание текста возможно при наличии чёткого изображения, где все буквы визуально отделены одна от другой. В случае «замыленного» изображения, в котором буквы связаны друг с другом, имеют витиеватый характер, распознавание будет некачественным. В некоторых случаях вы и вовсе получите отсутствие какого-либо результата.
Работа с такими сервисами проста:
- Вы переходите на такой ресурс, и загружаете на него изображение с текстом.
- Указываете язык, на котором написан имеющийся на изображении текст.
- При наличии на ресурсе возможности, выбираете ту часть изображения, на которой расположен нужный текст.
- Затем запускаете процедуру распознавания онлайн, и обычно через пару секунд получаете результат.
Давайте разберём сервисы, позволяющие выделить текст с графического изображения online.
Jinapdf.com – сервис для качественного распознавания текста
Американский ресурс jinapdf.com от «Convert Daily LLC» – это один из наиболее эффективных ресурсов для распознавания текста онлайн. Его предназначение – быстрая и эффективная конвертация файлов из одного формата в другой. При этом ресурс умеет распознавать текст с изображения, хорошо распознаёт латиницу и кириллицу, поддерживает русскоязычный интерфейс, бесплатен и быстр. Для копирования текста с изображения online этот ресурс станет хорошим выбором.
- Перейдите на jinapdf.com;
- Кликните на «Выберите язык», и укажите язык, на котором написан текст на картинке;
- Нажмите на «Выберите файл», и загрузите файл с изображением на ресурс;
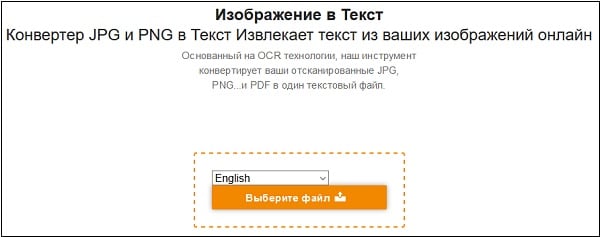
Нажмите на «Выберите файл» для загрузки изображения на ресурс
Newocr.com – поможет скопировать надпись с любой картинки
Другой качественный ресурс, о котором мы хотим рассказать – это newocr.com. Его возможности позволяют распознать текст с 106 языков, он бесплатен и не требует регистрации. Количество загрузок пользовательских фотографий на ресурс неограниченно, сервис хорошо распознаёт изображение с несколькими слоями. Полученный результат можно скачать на ПК, отредактировать в Гугл Докс, перевести через Google или Bing Переводчик.
Для работы с сервисом выполните следующее:
- Запустите newocr.com;
- В графе «Recognition language» (языки распознавания) выберите языки, на которых написан текст в изображении;
- Нажмите на «Обзор», и укажите сервису путь к нужному изображению;
- Для загрузки картинки на ресурс и её распознавания кликните на кнопку «Upload+OCR»;
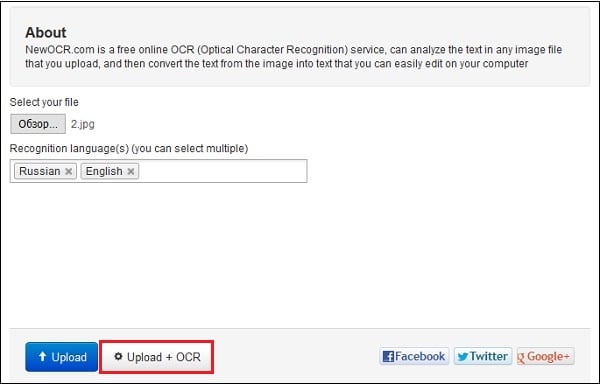
Нажмите на «Upload + OCR» для загрузки и распознавания текста

Для сохранения результата нажмите на «Download»
I2ocr.com – бесплатная идентификация текста онлайн
I2OCR – это бесплатный OCR-сервис, позволяющий выполнить идентификацию текста с изображения online. Его возможности позволяют извлечь текст с изображения онлайн для его последующего редактирования, форматирования, индексирования, поиска или перевода. Сервис распознаёт более 60 языков, поддерживает распознавание нескольких языков на одном изображении, многоколонный анализ документов, бесплатную загрузку неограниченного количества изображений.
Для работы с сервисом выполните следующее:
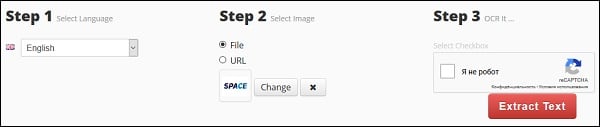
- Выполните вход на i2ocr.com;
- В графе «Select language» выберите язык распознавания;
- Нажмите на кнопку «Select image» в центре, и загрузите изображение на ресурс;
- Поставьте галочку рядом с надписью «Я не робот»;
- Нажмите на «Extract Text» для получения результата (будет отображён внизу).
Convertio.co – ресурс для копирования надписей с изображений
Ресурс convertio.co – это популярный онлайн-конвертер, имеющий интернациональный характер. С его помощью можно провести конвертацию шрифтов, видео и аудио, презентации и архивы, изображений, документов. Доступна здесь и функция OCR, которой мы и воспользуемся. Бесплатно можно распознать 10 страниц (изображений), за большее количество придётся доплачивать.
- Запустите convertio.co;
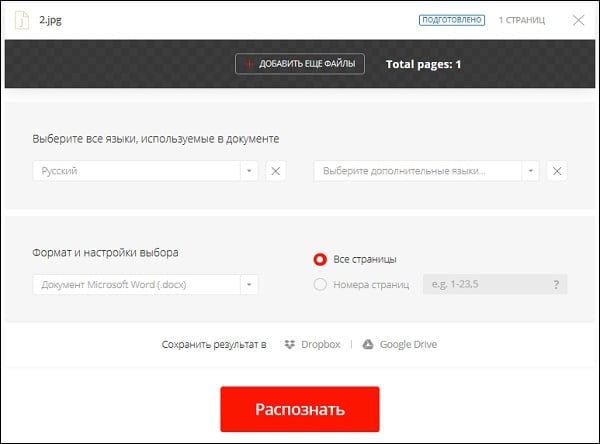
- Нажмите на «С компьютера» для загрузки изображения на ресурс;
- Чуть ниже выберите язык для распознавания (при необходимости активируйте дополнительные языки). Также выберите тип документа, в который будет трансформирован распознаваемый текст;
- Нажмите внизу на «Распознать»;
Настройки распознавания на convertio.co
Img2txt.com – русскоязычный сервис для распознавания текста
И последний сервис, о котором я хочу рассказать – это img2txt.com . Сервис был запущен в 2014 году, прошёл несколько стадий улучшения своего функционала, и ныне обладает довольно неплохим качеством распознавания. Здесь имеется русскоязычный интерфейс, что придётся по вкусу отечественному пользователю.
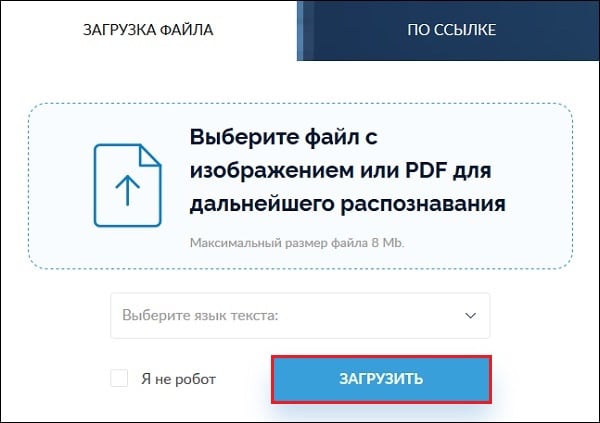
- Перейдите на img2txt.com;
- Кликните на «Выберите файл с изображением» и загрузите изображение с текстом на ресурс;
- Выберите язык текста для распознавания;
- Поставьте галочку рядом с надписью «Я не робот» (капча), и нажмите на «Загрузить»;
Загрузите файл на ресурс