

Сортировка вставками (Insertion sort) – простой алгоритм сортировки, при которой очередной элемент добавляется всегда в конец списка, а затем перемещается в начало списка до тех пор, пока он меньше предыдущего элемента.
Таким образом, формально, находится правильное место для вставки (например, сортировка карточек в библиотеке). Этот алгоритм будет иметь следующую последовательность шагов.
1. Шаг инициализации. Массив из одного элемента является уже отсортированным по возрастанию и выступает в виде начального списка.
2. Шаг итерации. Для всех последующих элементов со второго по n-1, очередной элемент i сравнивается со всеми предыдущими элементами от 0 до (i-1), пока текущий элемент i меньше или равен предыдущему. После этого будет найдена позиция для вставки или будет достигнуто начало списка. После этого элемент вставляется в найденную позицию.
3. Шаг выхода. Шаг итерации продолжается до тез пор, пока не будут просмотрены все элементы массива.
Пусть дан следующий массив:
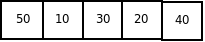



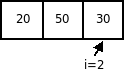

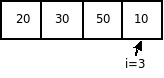


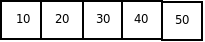
Анализ вычислительной сложности показывает, что в любом случае необходимо произвести (n-1) проход. В каждом из этих проходов в наилучшем случае, когда массив отсортирован по возрастанию, потребуется одно сравнение. В этом случае перестановок не будет, а вычислительные затраты будут
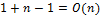 .
.
В наихудшем случае, когда массив отсортирован по убыванию, на каждый из (n-1) проходов потребуется i сравнений с предыдущими элементами  . Вычислительная сложность пропорциональна
. Вычислительная сложность пропорциональна  . В среднем, на каждом проходе потребуется на половину меньше. Следовательно, в среднем
. В среднем, на каждом проходе потребуется на половину меньше. Следовательно, в среднем 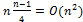 . Вычислительная сложность все равно пропорциональна
. Вычислительная сложность все равно пропорциональна  .
.
Блок-схема алгоритма сортировки вставками имеет вид:

Реализовать данный алгоритм на языке С++ можно следующим образом:
template
void InsertSort(T *A, const int n)
int j;
for (int i = 1; i 0 && Temp
2. Шаг итерации. Для всех элементов начиная с позиции ScanUp до конца, ScanUp увеличивается на 1, пока не будет найден элемент, который больше серединного элемента или, пока не будет достигнут конец списка. Таким образом, ScanUp будет указывать на элемент, который находится не в своем подсписке, т.е. все элементы до ScanUp будут меньше или равны серединному. После этого индекс ScanDown уменьшается на 1, пока не будет найден элемент меньший или равный серединному, либо пока не будет достигнуто начало списка (ScanDown ScanDown, то это означает, что каждый элемент находится в своем подсписке и их переставлять друг с другом нет необходимости. В противном случае элементы переставляются местами.
3. Шаг выхода. Шаг итерации выполняется до тех пор, пока ScanDown не станет меньше ScanUp. Это означает, что весь список разделен на две части: со значениями меньшими или равными серединному элементу и со значениями большими серединного элемента. Их разделяет позиция индекса ScanDown. После этого серединный элемент в нулевой позиции и элемент с индексом ScanDown переставляются местами.
4. Шаг рекурсии. Шаги 1-3 повторяются для левого подсписка с элементами от low до ScanDown-1 и правого – от ScanDown+1 до high до тех пор, пока список не останется пустым или одноэлементным.
Пусть исходный массив имеет вид:

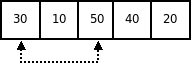





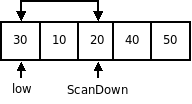


  |  |
Рекурсия продолжается пока не будет одноэлементный список или пустой.
Анализ вычислительной сложности в общем случае затруднен. Если исходный массив можно представить в виде бинарного дерева, то в общем случае необходимо будет осуществить 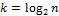 рекурсивных вызовов. Для каждого из этих вызовов, на первом необходимо просмотреть n элементов находящихся в двух подсписках. Среднее число сравнений будет
рекурсивных вызовов. Для каждого из этих вызовов, на первом необходимо просмотреть n элементов находящихся в двух подсписках. Среднее число сравнений будет  . На второй итерации надо будет просмотреть 4 подсписка. В каждом из которых нужно сделать
. На второй итерации надо будет просмотреть 4 подсписка. В каждом из которых нужно сделать  сравнений. Общее число будет
сравнений. Общее число будет 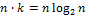 . Таким образом, затраты будут пропорциональны
. Таким образом, затраты будут пропорциональны  . Если массив отсортирован по возрастанию или убыванию, вычислительные затраты не изменяются. Наихудший случай появляется, когда в каждом подсписке серединный элемент оказывается максимальным или минимальным. Тогда один из подсписков будет оставаться пустым, а во втором подсписке будут находиться всегда n элементов. В этом случае преимущество «быстрой сортировки» исчезает и появляется обычная сортировка выборкой, затраты которой
. Если массив отсортирован по возрастанию или убыванию, вычислительные затраты не изменяются. Наихудший случай появляется, когда в каждом подсписке серединный элемент оказывается максимальным или минимальным. Тогда один из подсписков будет оставаться пустым, а во втором подсписке будут находиться всегда n элементов. В этом случае преимущество «быстрой сортировки» исчезает и появляется обычная сортировка выборкой, затраты которой 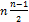 . Таким образом, в патологическом случае затраты станут пропорциональны .
. Таким образом, в патологическом случае затраты станут пропорциональны .
В отличие от других видов сортировки данный метод является самым быстрым, однако, если не устраивает патологический случай, то можно воспользоваться пирамидальной сортировкой. Она имеет туже вычислительную сложность, и у нее нет никаких ограничений. Затраты всегда остаются , в независимости от исходных данных.
Блок-схема алгоритма быстрой сортировки имеет следующий вид:

Реализовать данный алгоритм на языке С++ можно следующим образом:
template
void QuickSort(T *A, const int low, const int high)
Выбирая алгоритм сортировки для практических целей, программист, вполне вероятно, остановиться на методе, называемом «Быстрая сортировка» (также «qsort» от англ. quick sort). Его разработал в 1960 году английский ученый Чарльз Хоар, занимавшийся тогда в МГУ машинным переводом. Алгоритм, по принципу функционирования, входит в класс обменных сортировок (сортировка перемешиванием, пузырьковая сортировка и др.), выделяясь при этом высокой скоростью работы.
Отличительной особенностью быстрой сортировки является операция разбиения массива на две части относительно опорного элемента. Например, если последовательность требуется упорядочить по возрастанию, то в левую часть будут помещены все элементы, значения которых меньше значения опорного элемента, а в правую элементы, чьи значения больше или равны опорному.
Вне зависимости от того, какой элемент выбран в качестве опорного, массив будет отсортирован, но все же наиболее удачным считается ситуация, когда по обеим сторонам от опорного элемента оказывается примерно равное количество элементов. Если длина какой-то из получившихся в результате разбиения частей превышает один элемент, то для нее нужно рекурсивно выполнить упорядочивание, т. е. повторно запустить алгоритм на каждом из отрезков.
Таким образом, алгоритм быстрой сортировки включает в себя два основных этапа:
- разбиение массива относительно опорного элемента;
- рекурсивная сортировка каждой части массива.
Разбиение массива.
Еще раз об опорном элементе. Его выбор не влияет на результат, и поэтому может пасть на произвольный элемент. Тем не менее, как было замечено выше, наибольшая эффективность алгоритма достигается при выборе опорного элемента, делящего последовательность на равные или примерно равные части. Но, как правило, из-за нехватки информации не представляется возможности наверняка определить такой элемент, поэтому зачастую приходиться выбирать опорный элемент случайным образом.
В следующих пяти пунктах описана общая схема разбиения массива (сортировка по возрастанию):
- вводятся указатели first и last для обозначения начального и конечного элементов последовательности, а также опорный элемент mid;
- вычисляется значение опорного элемента (first+last)/2, и заноситься в переменную mid;
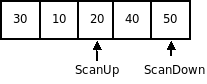
- указатель first смещается с шагом в 1 элемент к концу массива до тех пор, пока Mas[first]>mid. А указатель last смещается от конца массива к его началу, пока Mas[last]

Первый элемент левой части сравнивается с mid. Mas[1]>mid, следовательно firstостается равным 1. Далее, элементы правой части сравниваются с mid. Проверяется элемент с индексом 8 и значением 8. Mas[8]>m >

Алгоритм снова переходит к сравнению элементов. Второй элемент сравнивается с опорным: Mas[2]>m >

Алгоритм снова переходит к сравнению элементов. Третий элемент сравнивается с опорным: Mas[3] m >

На этом этап разбиения закончен. Массив разделен на две части относительно опорного элемента. Осталось произвести рекурсивное упорядочивание его частей.
Рекурсивное доупорядочивание
Если в какой-то из получившихся в результате разбиения массива частей находиться больше одного элемента, то следует произвести рекурсивное упорядочивание этой части, то есть выполнить над ней операцию разбиения, описанную выше. Для проверки условия «количество элементов > 1», нужно действовать примерно по следующей схеме:
Имеется массив Mas[L..R], где L и R – индексы крайних элементов этого массива. По окончанию разбиения, указатели first и last оказались примерно в середине последовательности, тем самым образуя два отрезка: левый от L до last и правый от first до R. Выполнить рекурсивное упорядочивание левой части нужно в том случае, если выполняется условие L
Быстрая сортировка (англ. quicksort ), часто называемая qsort (по имени в стандартной библиотеке языка Си) — широко известный алгоритм сортировки, разработанный английским информатиком Чарльзом Хоаром во время его работы в МГУ в 1960 году.
Один из самых быстрых известных универсальных алгоритмов сортировки массивов: в среднем O(n log n) обменов при упорядочении n элементов; из-за наличия ряда недостатков на практике обычно используется с некоторыми доработками.
Отличительной особенностью быстрой сортировки является операция разбиения массива на две части относительно опорного элемента. Например, если последовательность требуется упорядочить по возрастанию, то в левую часть будут помещены все элементы, значения которых меньше значения опорного элемента, а в правую элементы, чьи значения больше или равны опорному. Вне зависимости от того, какой элемент выбран в качестве опорного, массив будет отсортирован, но все же наиболее удачным считается ситуация, когда по обеим сторонам от опорного элемента оказывается примерно равное количество элементов. Если длина какой-то из получившихся в результате разбиения частей превышает один элемент, то для нее нужно рекурсивно выполнить упорядочивание, т. е. повторно запустить алгоритм на каждом из отрезков.
Таким образом, алгоритм быстрой сортировки включает в себя два основных этапа:
- разбиение массива относительно опорного элемента;
- рекурсивная сортировка каждой части массива.
| Худшее время |
|---|
O(n log n) (обычное разделение)
или O(n) (разделение на 3 части)
O(n) вспомогательных
O(log n) вспомогательных
Реализация алгоритма на различных языках программирования:
Работает для произвольного массива из n целых чисел.
Исходный вызов функции qs для массива из n элементов будет иметь следующий вид.
Java/C#
C# с обобщенными типами, тип Т должен реализовывать интерфейс IComparable
C# с использованием лямбда-выражений
Быстрая сортировка на основе библиотеки STL.
Java, с инициализацией и перемешиванием массива и с измерением времени сортировки массива нанотаймером (работает только если нет совпадающих элементов массива)
JavaScript
Python
С использованием генераторов:
Haskell
Математическая версия — с использованием генераторов:
Common Lisp
В отличие от других вариантов реализации на функциональных языках, представленных здесь, приводимая реализация алгоритма на Лиспе является "честной" — она не порождает новый отсортированный массив, а сортирует тот, который поступил ей на вход, "на том же месте". При первом вызове функции в параметры l и r необходимо передать нижний и верхний индексы массива (или той его части, которую требуется отсортировать). Код использует "императивные" макросы Common Lisp’а.
Pascal
В данном примере показан наиболее полный вид алгоритма, очищенный от особенностей, обусловленных применяемым языком. В комментариях показано несколько вариантов. Представленный вариант алгоритма выбирает опорный элемент псевдослучайным образом, что, теоретически, сводит вероятность возникновения самого худшего или приближающегося к нему случая к минимуму. Недостаток его — зависимость скорости алгоритма от реализации генератора псевдослучайных чисел. Если генератор работает медленно или выдаёт плохие последовательности ПСЧ, возможно замедление работы. В комментарии приведён вариант выбора среднего значения в массиве — он проще и быстрее, хотя, теоретически, может быть хуже.
Внутреннее условие, помеченное комментарием «это условие можно убрать» — необязательно. Его наличие влияет на действия в ситуации, когда поиск находит два равных ключа: при наличии проверки они останутся на местах, а при отсутствии — будут обменены местами. Что займёт больше времени — проверки или лишние перестановки, — зависит как от архитектуры, так и от содержимого массива (очевидно, что при наличии большого количества равных элементов лишних перестановок станет больше). Следует особо отметить, что наличие условия не делает данный метод сортировки устойчивым.
Устойчивый вариант (требует дополнительно O(n)памяти)
Быстрая сортировка, нерекурсивный вариант
Нерекурсивная реализация быстрой сортировки через стек. Функции compare и change реализуются в зависимости от типа данных.